Following the 6 January attack on the US Capitol, law enforcement quickly arrested dozens of protestors. How? The participants’ widespread use of social media to document and share their experiences provided an overwhelming amount of readily-available information for federal investigators to comb through and use to identify the rioters.
Individuals and hacktivists also have made use of that data to engage in vigilante investigative and analytical activities. One of the most notable is hacktivist @donk_enby, who in the days following the attack, reported on Twitter her efforts to archive terabytes of videos and images posted to Parler. She boasted of being able to identify “deleted” content that was previously posted by users. She then shared the metadata openly, to include location and time information for each post. Her work was completed and shared just hours before AWS kicked Parler off of their servers.
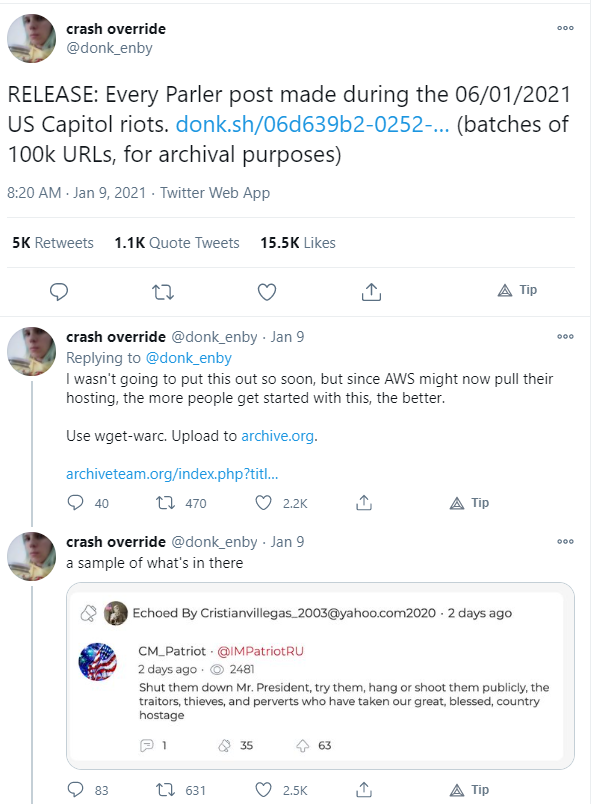
A number of users and groups–each with a range of agendas and capabilities–have picked up this data for further analysis. World-class open source intelligence organizations like @bellingcat are spearheading a comprehensive analysis using this data to map movements of the day, and assist in identifying individuals for further investigation and prosecution by law enforcement. Journalists are doing similar work–aligning images and video, spatially and temporally–to create a coherent narrative around the events on 6 January 2021.
Depending on how public these users and groups make the results of their work, vigilantes, criminals, and activists will use the data, too. The fact that participants in President Trump’s “Stop-the-Steal” rally on January 6th have received death threats in response to their social media posts, signals what may become a worrisome and dangerous trend in the weeks and months ahead. On its own, forensic investigation and analysis of images and posts can be very powerful. But the addition of the Parler metadata into the mix creates a whole new ballgame.
The New Ballgame
For those of you who have read the New York Times piece about how mobile device location data is collected via software packages that are embedded in apps like Parler, you know these packages capture “the places you go every moment of the day, whom you meet with or spend the night with, where you pray, whether you visit a methadone clinic, a psychiatrist’s office or a massage parlor.” This location data is gathered on a massive scale (billions of points daily for the US alone), with high accuracy and precision, from millions of users. When viewed through this lens, the term Big Data feels insufficient. The term Big Brother Data may be more appropriate.
But before you dust off your tin foil hat or start pointing fingers, be aware that this data doesn’t “come from a telecom or giant tech company, nor [does] it come from a governmental surveillance operation.” It comes from you. Yes, you read that correctly. You likely have been freely sharing your every move (or close to it) with these companies for years.
Well that seems ridiculous, doesn’t it? You would never do such a naiive thing! But odds are, if you have a smartphone, and have ever selected “I Agree” without reading or comprehending the terms of use agreement for an app, and then used that app, you have. Possibly many, many times over. Although your name is obscured by a unique identifier that isn’t remotely human-readable, it does differentiate your movements and activities from your family members, friends, and colleagues and allows them to be tracked over time.
As the NYT article points out, your location data is collected, bought, and sold by data companies in order to push relevant advertisements to you. It is a billion dollar industry most of us are influenced by daily, yet few have ever heard of. And while Apple is taking steps to require privacy “nutrition labels” for all apps available via their store so that consumers can be more aware of what they are sharing before blindly clicking “I Agree,” things are unlikely to get better for consumer privacy in the United States any time soon.
Should We ID People?
To answer our core question, we have to start with the data itself. Laws and regulations aren’t terribly helpful here, so we have to look at it through a logical and ethical lens. The ethical framework for the use of Big Data by private citizens or corporations in this country is not well defined, which makes it dangerously subjective. Private industry’s use of this type of data is based on its perception of risk: am I creating a liability that could cause me to lose customers, trust, employees (i.e., money) in the future? The lack of laws or guidelines leaves the burden primarily on organizations to do what is right. But organizational decisions often are driven by pressures to do what is possible and to create the most value, at a tolerable risk tradeoff.
So what should that framework look like? How do we go about instituting one in this country, recognizing that this will take time?
And, what should we do right now? Are the actions by data vigilantes permissible or laudable? Do we need more of them? Or, is law enforcement the only type of organization with the authority to engage in such activities under the 4th Amendment? As citizens, do we want law enforcement to have the capabilities to do this type of analysis and investigation at-scale? What if law enforcement has limited resources with which to be able to do so? With more violence planned for Inauguration Day, are we facing a “ticking time bomb” scenario, or exigent circumstances, that enable data vigilantes and law enforcement to work together in an attempt to prevent further harm?

Sure, odds are that you, me, and many, many participants in the January 6th attack on the capitol have willingly shared data with whatever app, but we did so with an expectation of privacy about our identity and personal information. We did so with an expectation that it wouldn’t (and couldn’t) be used to violate individual privacy unless we were suspected of committing a crime. Even then, this info wouldn’t be shared with the public unless charges were filed, and even then, it would be in the hands of law enforcement who have a duty of care over it as sensitive information and evidence.
The leaked Parler metadata muddies these waters because it is “Big Brother Data” that was brought into the public domain by a hacktivist. She exploited a bug in the Parler platform with the intent of exposing information about the activities of its users so that they could be identified. The exposure of this data might not “violate” due process, but it definitely sidesteps it. And as we all know: two wrongs don’t make a right.
So, instead of asking “What can we do?” the guiding question must be, “What should we do?”
For private citizens, practicing analytic restraint and fighting an emotional response is paramount at this time, especially when you think you could do a lot of “good” in the process. That “good,” however, isn’t sufficient justification because it is highly circumstantial. For example, there is a “fruit of the poisonous tree” argument that could make the evidence gathered by well-intentioned data vigilantes inadmissible in a court of law. That could conceivably result in the direct opposite of what you intend: the arrest and prosecution of a criminal involved in the January 6th attack on the Capitol.
For private corporations with intelligence chops, sure, this could be a lucrative and meaningful undertaking, making it very tempting. But for all of the reasons stated above, as well as recent increased interest in investigating contracts between government agencies and location data companies, it seems that while groups might turn a blind eye in the near term, in the mid-to-long-term the exposure risk is very real.
Further, this type of activity ultimately erodes civil liberties, the very protections afforded to us by the Constitution itself, and our shared values as a nation. Despite the historic nature of recent events, they do not legitimize private citizen or corporate use of app-based big data that is unavailable in the public domain to identify people even if we find ourselves in exigent circumstances. In the long-term, the development of national consumer privacy protection laws and guidelines that protect civil liberties and more closely follow the model in place in California and the E.U. should be pursued aggressively by the next administration.

